

داده کاوی فرایند کشف اطلاعات پیش بینی کننده از تجزیه و تحلیل پایگاه های داده بزرگ است. برای یک دانشمند داده ، داده کاوی می تواند یک کار مبهم و دلهره آور باشد. برای جمع آوری داده های خام و کسب موفقیت آمیز از آن ، به مجموعه مهارت ها و دانش متنوعی از بسیاری از تکنیک های داده کاوی نیاز است.
شما می توانید مبانی آمار و زبانهای برنامه نویسی مختلف را که می توانند در مقیاس بندی داده کاوی به شما کمک کنند با استفاده از الگوریتم های Data Mining درک کنید. در ادامه بیشتر با موضوع آموزش داده کاوی و الگوریتم های آن در زبان برنامه نویسی پایتون آشنا خواهیم شد.
داده کاوی (Data Mining) چیست؟
قبل از هر چیز با مفهوم و معنی داده کاوی در ابتدا آشنا شویم تا در ادامه به توضیح نحوه عملکرد آن در الگوریتم های تعریف شده برسیم :
تعریف : داده کاوی یا Data Mining در اصل به معنی استخراج اطلاعات الگوها و بررسی روابط مشخص بر مقدار زیادی از حجم داده ها در یک یا چند بانک اطلاعاتی حجیم است.
بسیاری از ما داده کاوی را هم معنی کلمات رایج مثل کشف دانش در پایگاه دادهها می دانیم ولی داده کاوی، پایگاه های اطلاعاتی و مجموعه حجیم داده ها را هنگام کشف و استخراج، مورد تحلیل قرار می دهد.
در داده کاوی تفاوت مهم در مقیاس، بزرگی و تنوع در زمینه ها و کاربرد های آن و همینطور در ابعاد و اندازه های داده های امروزی است، که تقاضا را برای روش های به صورت ماشینی مربوط به یادگیری، مدل سازی، و آموزش را بیش از پیش مورد توجه قرار داده است.

یک نتیجه مطلوب حاصل از داده کاوی ، ایجاد مدلی از مجموعه داده های معین است که می تواند بینش خود را به مجموعه داده های مشابه تعمیم دهد. یک نمونه واقعی از یک برنامه کاربردی داده کاوی موفق را می توان در تشخیص خودکار کلاهبرداری از بانک ها و موسسات اعتباری مشاهده کرد.
در مقالات قبلی به نقش مهم زبان برنامه نویسی پایتون در یادگیری ماشین و روش های پیاده سازی آن اشاره کرده ایم و در حقیقت می توانیم با استفاده از آموزش پایتون مدرسه قباد به بررسی دقیق الگوریتم های داده کاوی بپردازیم.
کاربردهای داده کاوی در زندگی
به عنوان نمونه برای درک بیشتر در مورد داده کاوی و کاربرد آن در زندگی امروزی میخواهیم مثالی بزنیم :
در بانکی که حساب دارید به احتمال زیاد در صورت مشاهده هرگونه فعالیت مشکوک مانند برداشت مکرر دستگاه های خودپرداز یا خریدهای بزرگ در شهر های ایران خارج از محل اقامت و استان شما ، به شما هشدار می دهد.
این عملکرد چگونه با داده کاوی ارتباط دارد؟ دانشمندان داده این سیستم را با استفاده از الگوریتم هایی برای طبقه بندی و پیش بینی کلاهبرداری بودن یک معامله با مقایسه آن با الگوی تاریخی اتهامات کلاهبرداری و غیر کلاهبرداری ایجاد می کنند. این مدل “می داند” که اگر در استان تهران زندگی می کنید ، به احتمال زیاد خریدهای چند میلیونی و یا چند میلیاردی که از یک استان کم جمعیت و دور افتاده مثلا در شهر زابل گرفته شده قانونی نخواهد بود. جالب است نه؟!
این تنها یکی از ویژگی های مهم از برنامه های قدرتمند داده کاوی است. سایر کاربردهای داده کاوی شامل توالی ژنومی (نقشه ژنتیک) ، تجزیه و تحلیل شبکه های اجتماعی یا تصویر برداری از جرم و جنایت است.
اما رایج ترین مورد استفاده برای تجزیه و تحلیل جنبه های چرخه زندگی مصرف کننده است. شرکت ها از داده کاوی برای کشف نوع ترجیح مصرف کننده ، طبقه بندی مصرف کنندگان مختلف بر اساس فعالیت خرید آنها و تعیین اینکه چه چیزی برای مشتری با درآمد بالا مورد قبول است استفاده می کنند. در اصل اطلاعاتی که می تواند تأثیرات عمیقی بر بهبود جریان درآمد و کاهش هزینه ها داشته باشد را به شرکت های تولید محصول و فروشگاه های بزرگ برای فروش بیشتر ارائه می دهد.
در تمام زمینه های علمی و حتی آموزش برنامه نویسی می توان از داده های بدست آمده از گروه ها و شرکت هایی که در زمینه داده کاوی فعالیت می کنند به پیشرفت بهتری برسید.
بررسی تکنیک های داده کاوی
روش های مختلفی برای ایجاد مدل های پیش بینی از مجموعه داده ها وجود دارد و یک دانشمند داده باید مفاهیم پشت این تکنیک ها و همچنین نحوه استفاده از کد برای تولید مدل ها و تجسم موارد مشابه را درک کند. این تکنیک ها عبارتند از :
- تحلیل رگرسیون : شامل برآورد روابط بین متغیر ها با بهینه سازی کاهش خطا.
- بررسی طبقه بندی : تشخیص اینکه یک شی به چه دسته ای تعلق دارد. به عنوان مثال طبقه بندی ایمیل به عنوان هرزنامه یا قانونی ، یا مشاهده نمره اعتباری شخص و تأیید یا رد درخواست وام.
- تجزیه و تحلیل خوشه ای : یافتن گروه بندی طبیعی اشیاء داده بر اساس ویژگی های شناخته شده آن داده ها.
مثال : یک مثال را می توان در بازاریابی مشاهده کرد ، جایی که تجزیه و تحلیل می تواند گروه های مشتری با رفتار منحصر به فرد را نشان دهد که می تواند در تصمیم گیری های استراتژی مورد استفاده در یک شرکت آموزشی برای عنوان آموزش هوش مصنوعی قرار بگیرد.
- ارتباط و تجزیه و تحلیل همبستگی : این کاربرد به دنبال این است که ببینید آیا بین متغیرها روابط منحصر به فردی وجود دارد که به صورت صریح و آشکار نیستند؟
مثال : یک مثال می تواند مورد معروف نوشابه و پوشک باشد: مردانی که در پایان هفته در فروشگاه ها پوشک خریداری می کردند ، بیشتر خرید نوشابه انجام می دادند، بنابراین فروشگاه ها برای افزایش فروش نوشابه ها و پوشک ها آنها را در کنار یکدیگر قرار می دهند. تا بحال به این کاربرد از داده کاوی فکر کرده بودید؟!
- تجزیه و تحلیل بیرونی : بررسی نقاط دور افتاده برای بررسی علل و دلایل احتمالی برای هر مورد.
نمونه ای از تجزیه و تحلیل بیرونی در تشخیص تقلب است و اینکه این تحلیل به ما کمک می کند بفهمیم که آیا الگوی رفتاری خارج از هنجار تقلب است یا خیر؟!
استفاده از داده کاوی در پایتون
داده کاوی برای اکثر مشاغل اغلب با یک پایگاه داده معاملاتی و زنده انجام می شود که امکان استفاده آسان از ابزار های داده کاوی را برای تجزیه و تحلیل فراهم می کند.
یکی از نمونه های آن می تواند سرور پردازش تحلیلی آنلاین یا OLAP باشد که به کاربران امکان می دهد تجزیه و تحلیل چند بُعدی را در سرور داده ایجاد کنند. OLAP به کسب و کار اجازه می دهد تا داده ها را بدون بارگیری فایل های استاتیک جستجو و تجزیه و تحلیل کند، که در شرایطی که پایگاه داده شما به طور روزانه در حال رشد است می تواند مفید باشد.
خب در ادامه می خواهیم به موضوع مهمتری یعنی نحوه استفاده و انجام داده کاوی در پایتون با استفاده از دو الگوریتم که در بالا ذکر شد بپردازیم : تحلیل رگرسیون و تحلیل خوشه بندی.
مدل رگرسیون (Regression) در پایتون
قرار است با مدل تحلیل رگرسیون چه کارهایی انجام دهیم؟
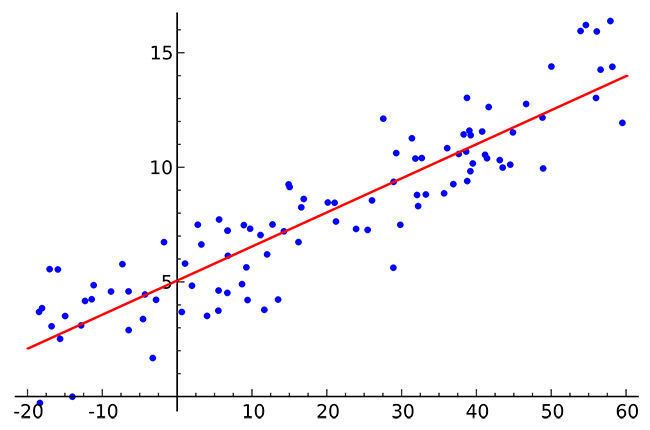
ما می خواهیم برآوردی از رابطه خطی بین متغیرها ایجاد کنیم ، ضرایب همبستگی را چاپ کنیم و خطی از بهترین تناسب را در مدل رگرسیون رسم کنیم.
مثال : برای نمونه از این تجزیه و تحلیل ، ما از داده های فروش خانه در مجموعه داده های یک شهرستان در تهران از پلتفرم Kaggle استفاده می کنیم. اگر با Kaggle آشنا نیستید ، باید بدانید این پلتفرم یک منبع فوق العاده برای یافتن مجموعه داده برای تمرین علم داده کاوی است. داده های این شهرستان فرضی دارای اطلاعاتی در مورد قیمت خانه و ویژگی های خانه است.
بنابراین باید ببینیم آیا می توانیم رابطه بین قیمت خانه و متر مربع خانه را تخمین بزنیم.
چطور از رگرسیون خطی استفاده کنیم؟
باید بدانیم تحلیل رگرسیون خطی یکی از روش های معمول، برای تحلیل و تجزیه داده های آماری بوده که از آن برای تشخیص این موضوع که چه رابطه ای خطی میان متغیر های وابسته و یک یا چند متغیر مجزا وجود دارد؟
همچنین رگرسیون های خطی به دو گونه رگرسیون های خطی چندگانه و رگرسیون خطی ساده تقسیم می شوند.
رگرسیون خطی چندگانه : از دو یا چند متغیر مجزا برای بررسی مقدار متغیر های وابسته استفاده می شود.
رگرسیون خطی ساده : از متغیر مستقل برای پیش بینی متغیر های وابسته استفاده می شود.
تفاوت بین این دو مدل در تعداد متغیر های مجرایی است که گرفته می شود و در هر دو مدل از یک متغیر وابسته استفاده می شود.
البته ذکر این نکته مهم است که شاید بخش سخت استفاده از مدل رگرسیون وقتی است که می خواهیم از میزان اشتباه تخمین زدن آن ممانعت کنیم.
مدل خوشه بندی (Clustering) در پایتون
چه کاری با خوشه بندی انجام خواهیم داد؟
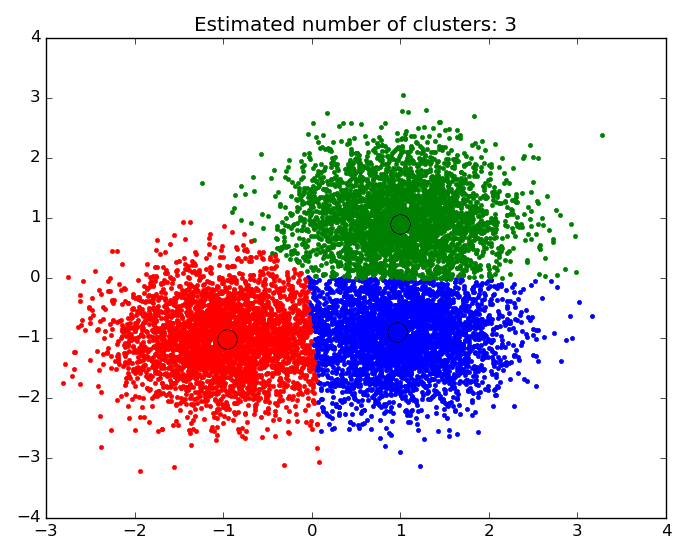
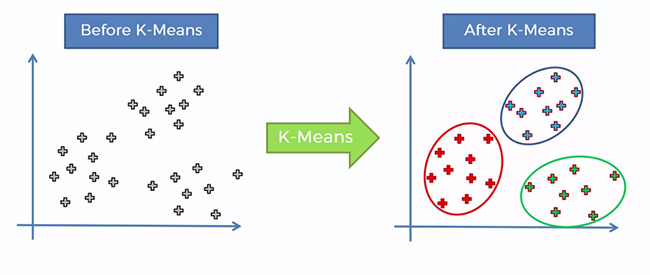
ما می خواهیم گروهی طبیعی برای مجموعه ای از اشیاء داده ایجاد کنیم که ممکن است به صراحت در خود داده ها بیان نشده باشد. تجزیه و تحلیل ما از داده های مربوط به فوران های یک آتشفشان است. این مورد شامل تنها دو ویژگی است ، زمان انتظار بین فورانها (دقیقه) و طول فوران (دقیقه). داشتن فقط دو ویژگی ، ایجاد یک مدل خوشه ای ساده با الگوریتمی به نام k-میانگین را آسان خواهد کرد که با استفاده از مدل خوشه بندی کار می کند.
در مدل خوشه بندی وظیفه گروه بندی مجموعه ای از اقلام وجود دارد به طوری که اقلام یک گروه به نحوی به هم متصل می شوند. سپس به هر گروه خوشه ای گفته می شود.
خوشه بندی اغلب در داده کاوی اکتشافی و تجزیه و تحلیل داده های آماری استفاده می شود. شما می توانید خوشه بندی را در بسیاری از برنامه ها مانند تشخیص الگو ، بینایی رایانه ، ترکیب داده ها و بیوانفورماتیک پیدا کنید.
هدف از انجام یک عملیات خوشه ای ، بدست آوردن خوشه هایی از نقاط است که نزدیک یکدیگر هستند. هنگامی که چندین نقطه در فاصله کمی از یکدیگر قرار دارند ، در یک خوشه قرار می گیرند، در حالی که اگر از هم دور باشند ، خوشه های متفاوتی خواهند داشت. اغلب فاصله های مورد استفاده عبارتند از Euclidean ، Cosine ، Jaccard ، Hamming و Edit.
خوشه بندی را می توان با استفاده از یکی از دو روش و استراتژی انجام داد :
خوشه بندی سلسله مراتبی : در این روش ، هر نقطه داده به عنوان خوشه شروع می شود. سپس الگوریتم شروع به پیوستن به خوشه هایی می کند که فاصله آنها از یکدیگر نزدیک است تا زمانی که به حد مشخصی برسد. این حد و حدود می تواند مجموعه ای از خوشه ها یا مجموعه ای از قوانین بر روی خوشه های مختلف باشد.
تخصیص نقطه : هر نقطه داده به یک خوشه از پیش تعیین شده اختصاص داده می شود که بر اساس آن بهترین تناسب را دارد. برخی از تغییرات این الگوریتم ها امکان تقسیم خوشه ای یا اتصال خوشه ای را فراهم می کند. برخی از الگوریتم های تعیین نقطه رایج مانند k-means و BFR (بردلی ، فیاض ، رینا) وجود دارد.
یکی از مشهورترین الگوریتم خوشه بندی الگوریتم k-means یا k-میانگین است و می توان آن را به راحتی با استفاده از Python و Sci-kit پیاده سازی کرد. شما همچنین می توانید با استفاده از آموزش انواع الگوریتم های داده کاوی مدرسه قباد به خوبی با مفهوم و کاربرد خوشه بندی آشنا شوید.
جمع بندی در زمینه الگوریتم های داده کاوی
با استفاده از داده کاوی که شامل تعدادی از تکنیک های مدل سازی پیش بینی کننده است می توانید از انواع نرم افزارهای داده کاوی استفاده کنید. در اوایل شاید با اشکالات بی شمار و پیام خطا و مواجه شوید، اما در تلاش برای یادگیری داده کاوی پیگیر و کوشا باشید. امیدوارم با مشاهده روند ایجاد مدلهای رگرسیون خوشه ای و خطی بالا ، متوجه شده باشید که داده کاوی قابل دستیابی است و می توانید با استفاده از آن فعالیت های خوب و کارآمدی در شغل حرفه ای و زندگی خود داشته باشید.
یادگیری بکارگیری این تکنیک ها با استفاده از زبان پایتون که از محبوبترین زبان های برنامه نویسی است برای شما می تواند اهمیت فوق العاده ای داشته باشد. استفاده از این تکنیک ها روی مجموعه داده های شخصی شما نیاز به تمرین و کوشش دارد. پیشنهاد ما استفاده از آموزش آنلاین مدرسه قباد برای دوره های آموزشی زبان پایتون است تا بتوانید با یادگیری آن بر مباحث داده کاوی مسلط شوید و از آنها در زمینه های مختلف که در بالا آورده شد استفاده کاربردی کنید.




